This week, we take a brief step into the world of GenAI Agents, having read “Principles of Building AI Agents” by Sam Bhagwat. 📚
The title is a terrible pun on a French TV show… 📺
The Book 📖️
I first learned about this book from a Tweet (“X”?) by Gergely Orosz. Out of curiosity, I downloaded the e-book and Sam kindly reached out to send across a physical copy. The need for a second edition just months after the first highlights how fast this space is moving.
It is a short read (2-3 hours) for technical readers that introduces a lot of breadcrumbs for people to go away and read more on. This means that by the end, you are not an expert, but carry a lot of the terms you need to do research and have conversations about the topic. It uses a top-down approach, building on top of LLMs, not explaining their foundations. The book is available in virtual or physical form. I am not being sponsored to write this - I just think it is great organic marketing and enjoy shorter reads.
Mastra is a company building a framework for building AI Agents and orchestrating them with workflows. Sam is a co-founder of the Gatsby web framework, and is taking an interesting bet on the TypeScript community as the place to start, with some early adoption examples.
In the next few sections, I’ll go over some terminology and takeaways.
 With thanks to Sam Bhagwat
With thanks to Sam Bhagwat
My Two Cents 🪙🪙
Like most waves of change and hype in the tech industry, the GenAI topic (coined as “Software 3.0”) causes divisiveness and scepticism. A lot of this reaction is justified. AI is not a new field - it has been around for decades. However, the release of ChatGPT in November 2022 created a fresh wave of noise around Generative AI.
Not long ago, we had a hype cycle around Blockchain and Cryptocurrency, which did not cause the revolution it promised. Blockchain often felt like a solution in search of a problem. GenAI has a plethora of tangible use cases, but needs to answer difficult questions in many areas before it can allay concerns. Namely surrounding the ethical, legal, socioeconomic, environmental and security impact of adopting this technology at scale. This is why the marketing can sometimes feel premature.
We could place a lot of these hype cycles along different points of the Gartner Hype Cycle. Blockchain and Cryptocurrency has found its niche after the hype has calmed down. GenAI could follow a similar path once the dust settles.
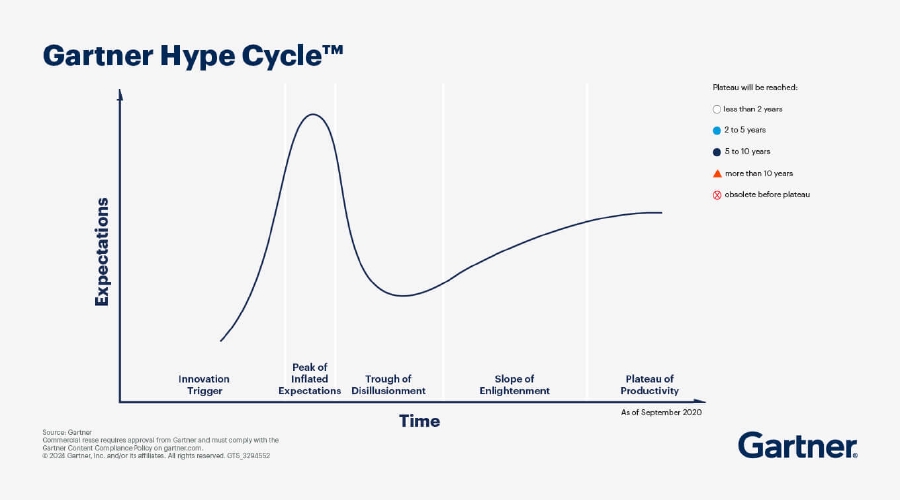 Image credit: Gartner
Image credit: Gartner
Jargon Busting 🧑🏫
The book introduces a lot of terminology. A true test of my understanding is whether I can now explain these concepts, which is what this section tries to achieve. Feel free to skip this section if you already have a good understanding.
Disclaimer ⚠️: I did have some background knowledge before reading this book, but not much. Academic readers might cringe at my attempt.
Glossary (Click to expand/collapse)
| Term | Definition | Example |
|---|---|---|
| LLM | Large Language Model. Probabilistic model trained on natural language which, when given a training corpus and input, will predict the most likely output using mathematical operations (e.g., matrix multiplication). These can be hosted or open source. | GPT-o1, Gemini, Llama |
| Prompt | Input to an LLM (commonly textual). These can be system or user level, which alters the scope (e.g. chat-level or individual query respectively). Prompt engineering is the practice of tailoring prompts to improve outputs. | "ChatGPT is cool!" |
| Token | Single raw chunk of text, taken from a larger document or textual input. | ["Chat", "G", "PT", " is", " cool", "!"] |
| Embedding / Vector | Transformed N-dimensional data structure representing the semantic meaning of a token or document. N is typically ~1536. This structure is used for similarity searches in N-dimensional space, which gives a numerical reading on how relevant the stored content is to the input prompt. | [0.12, ..., 0.95] |
| Context Window | The number of text chunks (tokens in the input and output) which the LLM can handle at any one time when processing a query. | GPT-4 = ~128k tokens. |
| Agent | A long-lived process that uses LLMs to perform tasks. They are allocated memory, invoke tools, access resources, and maintain context over time. | AI assistant that books meetings. |
| MCP | Model Context Protocol. Defined by Anthropic which stipulates how an agent should retrieve information from a third-party source. An MCP Server (hosted locally or remotely) declares its prompts, tools and resources for MCP clients to use. | Agent that is given instructions for connecting to a database to find weather information. |
| Tool (MCP) | Method for the agent to perform a task e.g. a web resource lookup, or calling another Agent. | fetch_weather(city) |
| Resource (MCP) | Data source used by the agent when performing tasks e.g. a database. | city_db |
| Prompt (MCP) | Templated instructions for the agent to perform a task e.g. details needed to call a tool or read from a resource. | "Search {query} in {resource}" |
| A2A | Agent To Agent Protocol. Defined by Google which stipulates how an Agent should communicate with another Agent, given that they are likely to have been built independently. | Agent1 asking Agent2 to extract data. |
| RAG | Retrieval Augmented Generation. A method for enhancing the information available to an LLM by performing on-demand embedding and similarity search with a vector database, to enrich a prompt with added stored context. | Retrieval of FAQs before answering queries. |
| Vector Database | A data store specialised in storage and retrieval of N-dimensional vectors. | pgvector, Pinecone |
| Agentic Workflow | An emerging practice which defines the tasks agents perform as steps in a deterministic orchestration workflow - commonly as a graph. | Fetch doc → summarise → email |
| Guardrail | Measures which inject additional context in the prompts given to LLMs to minimise the risk of them producing insecure or malicious output. More of a guidance mechanism than a watertight security measure. | Requesting that PII is not returned. |
| Eval | Methods for evaluating the effectiveness and accuracy of an Agent. | OpenAI Evals |
If you are a visual learner, then I am a fan of the ByteByteGo YouTube channel, which has a short video explaining some of these concepts.
Key Snippets ✂️
Despite being a short read, the book is full of advice from practical experience. This section summarises the main lessons.
Non-Determinism 🎲
Embrace not being sure of the answer. The book makes it very clear from the start that adopting this technology means being comfortable with non-determinism. A lot of Software Engineering is made easier by ensuring our programs exhibit repeatable, deterministic behaviour, so this introduces new challenges. In this field, the fundamental building blocks are probabilistic. The same input may generate infinite variations of output. Going back to the “Software 3.0” concept, even “2.0” (ML and Neural Nets) can be made deterministic (by fixing weights and parameters), so this marks a complete departure.
The idea of creating dynamic agents takes this one step further, as it might alter the agent environment such as the native spoken language and the LLM in use (based on business rules). This explodes the number of possible execution contexts.
Testing looks very different in a non-deterministic world. Instead of pass/fail semantics, Evals provide an interval of confidence ({0,1}) by which we can measure accuracy and reliability, and pick up on meaningful regressions or improvements. Because of this complexity, organizations often find it simpler to do A/B testing in production by measuring signals of user behaviour after deployment as a measure of effectiveness by proxy.
Because of all this non-determinism at the inner layer, imposing a graph-like structure on agentic workflows seems like a sensible method of constraining the probability space.
Size vs Cost vs Performance 💰
Start simple, then optimise. A trade-off is required between cost, performance and accuracy of the underlying models. Cheaper models will produce fast, less accurate responses, which might be enough for some use cases. The book advises starting with a costlier model (for greater accuracy) whilst volumes are low, then optimising. One should start by exhausting the LLM’s context window, before building agents, workflows or RAG pipelines.
There are clever UX techniques one might employ to make it look like the agent is doing useful work before it outputs a final answer, showing its workings and reasoning. A few solutions mentioned in the book stream their responses to a client via web-sockets, making use of tools like ElectricSQL before a full answer is generated.
Hosted vs Open-Source 🥷
As for the choice between hosted versus open source models (e.g., Claude vs DeepSeek), it is a natural reaction to want to see the inner workings of these models. I am reminded of the choice organizations need to make around adopting cloud computing. A hosted model provides much less of the hassle in getting up and running with this technology, which doesn’t differentiate a business from its competitors. On the surface there is not as much vendor lock-in (yet) compared to public cloud, but that may change. Each model has their own strengths, meaning that once a production system is tuned, it is hard to justify the effort to migrate. Some systems adopt a hybrid of models and route prompts based on rules (which is the equivalent of going “multi-cloud” to reduce concentration risk in my analogy).
Prompt Techniques 🔁
Structure matters. In most models there is a meaningful difference in output between “Zero-Shot” and “Chain Of Thought” prompting. Some models are specifically designed for everything-upfront interactions, rather than a chat. Much like a human would work better solving a problem if it had some examples, hints, and a schema (e.g., XML, JSON) to work with, so do LLMs.
The book also recommends trying a “seed crystal” approach, which involves asking an LLM how it should be prompted to do a task. Think of it like “meta-prompting”.
Infrastructure 🛠️
Agents are stateful and resource intensive. This constrains the infrastructure that companies can use to host them. Most serverless infrastructure will buckle under their resource usage, or time-out within 15 minutes. With the move to represent agents as workflows (e.g. Mastra, LangGraph), I do wonder if there is space to move orchestration into the infrastructure, much like we have seen with solutions like AWS Step Functions, which replaces orchestration in code. If a breakthrough were to happen in this space, it would change the cost-profile of this technology, linking it more dynamically to usage. This is much more attractive for firms with limited budgets (e.g. start-ups).
There are a multitude of ways to orchestrate and run agents, which makes it harder to move this concern to the infrastructure level.
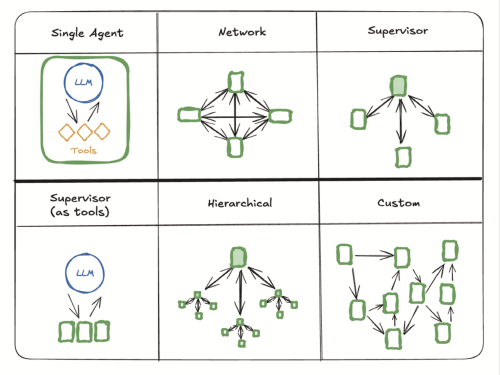 Example multi-agent architectures. Image credit: Principles of Building AI Agents
Example multi-agent architectures. Image credit: Principles of Building AI Agents
Takeaways ✍️
Having read the book and surrounding articles, I have some principles which I would adopt if I was to build a production agentic system.
- Measure 📐: Ensure that the technology solves a real problem (e.g. reducing time or cognitive load in manual processes). Make observability a day 1 concern (e.g., tool usage, task completion times). Do not rely solely on Eval scores - use metrics that describe user behaviour or feature adoption rates. Use feature flags and circuit breakers to rollback if metrics suggest a negative impact. Understand costs before the system grows.
- Build Incrementally 🛠️: Prioritise slower, more accurate models when volumes are low. Constrain possible outcomes by building workflows with very small scope tasks (e.g., each agent can access at most 1 tool).
- Human-First 🧍♂️: Keep humans in the loop. Don’t make Agents the only option (Klarna can attest here). Prioritise assistance over autonomy, allowing human overrides. Avoid introducing more risks than you started with.
- Security-First 🔐: Don’t rely on Guardrails as the only layer of defence. Do not expose data sources containing private data (even if you think the LLM has been told not to access it). Adopt AuthN/AuthZ techniques at each layer that allows for it. Store and rotate API keys as secrets outside the agent’s control. Physically isolate any data which does not serve a useful purpose for the task at hand. Monitor traffic (e.g. queries made to tools) and deny agents’ tool access based on anomalous activity (e.g. request limits breached, or a spike in “permission denied” errors).
Consensus 🌍
The current state of protocols in this space feels very much like an xkcd comic. Large companies are commercially incentivised to be the first to claim a standard, which leaves them half-defined on initial publication, relying on community contributions to improve.
In more established domains, we have neutral organizations which provide trust. IANA allocates IP addresses. The CVE registry standardises tracking of security vulnerabilities. SOC2 offers a set of controls for how organizations handle security and data. We would benefit from the same kind of unbiased, centralised certification for of what makes an Agent approved for production use.
 Image credit: xkcd
Image credit: xkcd
Summary 🧵
In this post, we reviewed the terminology and topics discussed in “Principles of Building AI Agents” by Sam Bhagwat. If this blog sounded interesting, I’d recommend downloading or buying the book directly, and following their work.
It is my first meaningful deep-dive into the engineering practices behind this technology. This space is clearly changing rapidly. If we look back on this post in 1-2 years, I would be interested to see what changes. Perhaps the majority of future use cases won’t even need an LLM.
As for next steps, there are some free courses on the topic by the likes of Mastra and Hugging Face, which I may dive into. I was thinking of writing a blog on how AI is changing my day-to-day role, but this article says it far better than I could.
If you have got to the end of this post and have recommendations, differing views or stories from real systems, please do get in touch.
Get in touch 📧
As I say in my About page, I would love to hear from you. If you got to the end of this post and have anything to share, please get in touch on LinkedIn or Twitter.